It happens often to me that in order to make an article clearer or more incisive, I may need to identify very long sentences in a draft and break them down to smaller, simpler units.
In 
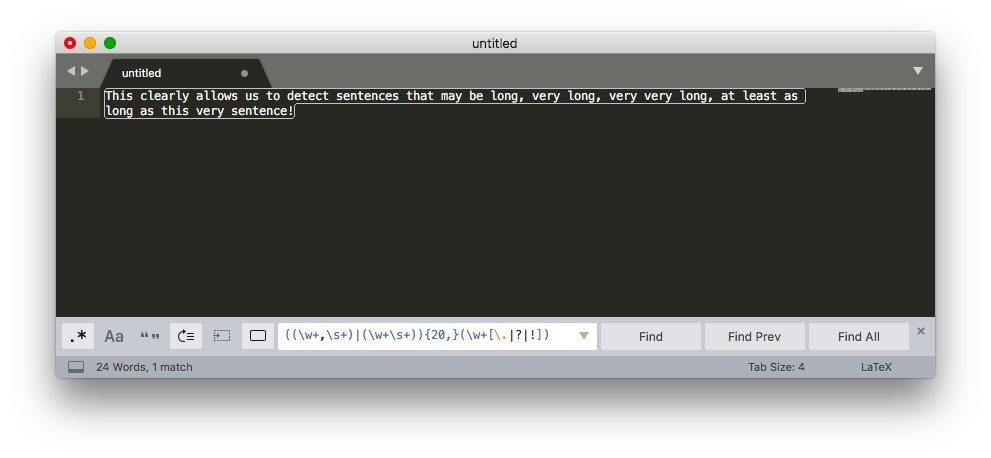
In editors that allow to search for regular expressions (such as Sublime Text or Texpad or others) the following snippet would allow us to search for sentences with more that 20 words:
<br>
((\w+,\s+)|(\w+\s+)){20,}(\w+[\.|?|!])<br>
It is not too hard to break this regular expression down to its elementary constituents. Let us just recall a few ideas concerning regular expressions
- remember that () enclose groups
- | indicates the OR operation
- \w+ corresponds to a series of one or more occurrences of an alphanumeric character (a word)
- \s+ corresponds to a series of one or more occurrences of spaces
- \. is the dot character
- {number_1, number_2} looks for at least number_1 repetitions of the previous element (with at most number_2 repetitions)
Therefore, in plain language, the above regular expression is
(a word followed by a comma followed by some space) OR (a word followed by some space) REPEATED AT LEAST 20 TIMES (a word followed by a full stop OR a question mark OR an exclamation mark)
This clearly allows us to detect sentences that may be long, very long, very very long, at least as long as this very sentence!

Leave a comment